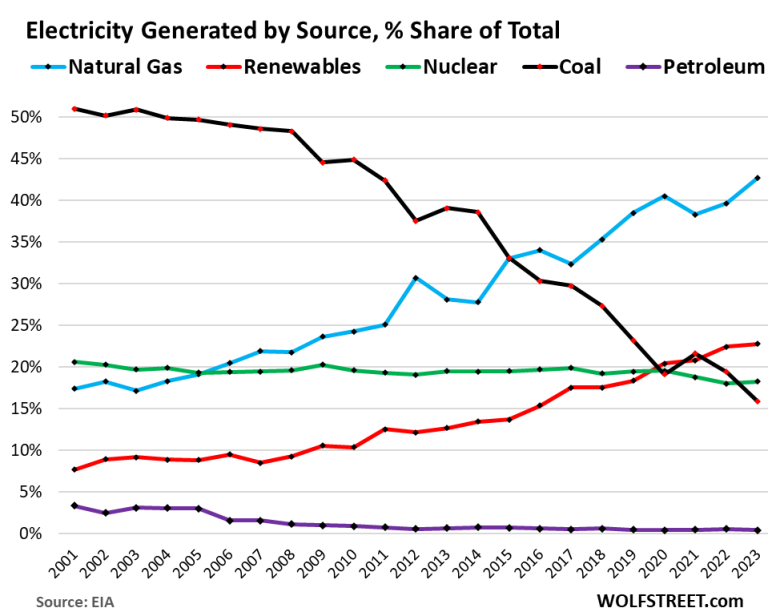
The neat thing about electric cars is that they get cleaner as the grid gets cleaner. If you bought an EV in 2015 (when this report was published) and were worried about the grid mix, I have good news for you. Electricity production from coal in the US is in the process of falling off a cliff, dropping to 15% of the electricity mix in 2023 from over 30% in 2015. https://wolfstreet.com/wp-content/uploads/2024/02/US-electri...
You're gonna have to locate yourself for this comment to make any sense. Plenty of places still get snow regularly in winter, and nothing humans can do will change that
Is there a plan to change this? Building on Electron should make it manageable to go cross-platform. 2026 will be the year of the Linux desktop, as the prophecies have long foretold.
Yes! Going cross-platform is on the roadmap, but right now we're focused on building out the feature set and improving the form factor.
Also yeah, Kernel refers to onkernel - they call it that because they're running the browsers in a unikernel. They're a great product and you should give them a look if you need hosted browsers!
In the early stage of a startup/product the most important thing is usually fast development loops, to add features and, most importantly, figure out what the product needs to be. It usually makes sense to focus on that, which means deferring later projects (such as porting to other platforms) which are also important, but aren't part of the figuring-out-the-product loop and so can come later.
This of course is frustrating for users who want the product but aren't using that platform. But also a good sign that someone wants the product enough to complain about this!
I am just wondering from technical standpoint. Their product doesn't seem like it would be doing anything OS-specific, so I would expect that it would be multi-platform without them having to do anything.
Yes, this was in fact an explanation of a joke. "In Soviet Russia, Rome is a poor city" requires both a currently-existing Soviet Russia, and Rome to be a part of it. Both of those are far-fetched. "Russia seems poised to invade Europe in the near future" is a bad explanation, since they are currently invading a country geographically in Europe.
I really expected this to be overblown clickbait, but the article delivers on the title about as well as it could. I have seen many more breathless articles on treatments that weren't already conducting human safety trials as well as having animal effectiveness trials concluded.
And yeah, it turns out that mammals can absorb oxygen through their butts. Weird
I know that rectal rehydration is a good method when sterile IV fluids are not available. Hopefully it's much safer than current ventilator or ECMO treatments.
Not really. Said tissues are well vascularized and therefore lend themselves to oxygen exchange. It’s just that the lungs are especially efficient for this.
it pretty common. a lot of people in my high school did this, or froze beer and inserted it to get rapidly wasted. the other classic is the tampon soaked in vodka
most of this was just done because drinks were too expensive or hard to get for high schoolers and they had to optimise their alcohol supplies
Don't treat an anecdote on the Internet like it actually happened. There have been people posting that they had friends of friends in college do this for twenty years. OP never did it but it definitely happened.
In this case it's high schoolers, half of whom most likely have no sexual experience but are fully willing to explore their anal cavity, having access to alcohol but not that much access.
They can get drunk off small amounts of alcohol, but it's such a small ration that they are freezing and destroying their limited amount of beer (which most high schoolers hate) to shove up their butts, to get drunk slightly faster? How much frozen beer can one butt fit? Is it really that much better than holding your nose and pounding it in front of your friends? Are high schoolers really going to parties with beer in their butts to maybe get a buzz of two beers from one butt beer because they only have access to one twelve pack, instead of just telling everyone how they are so wasted instead?
Not to mention the freezing point of ethanol is about -20 F. Just touching beer frozen solid enough to insert is going to instantly freeze surface water. You'd get your buttcicle maybe a quarter of the way in and it's going to start tearing layers of flesh off. I imagine it would make for hilarious fun party times.
As a guy who was gotten to by some male abusers as a child, I was simultaneously laughing uncontrollably and shutting my sphincter like a bank vault door as I read this. Never experienced anything like this before.
Okay, but what about humidity? I was excited to read about a failure mode where the moisture content of air mattered, or at least get mildly clickbaited into learning about a tool called Humidity. Instead there are no other references to humidity apart from the title
I chose "Debugging Humidity" as a metaphor for all the invisible, pervasive environmental factors that you have to deal with in the physical world. Latency, power flicker, interference, etc. It's the "stuff in the air" that messes up clean logic.
The title was actually inspired by a real incident where a device kept failing every afternoon. We eventually realized that condensation from the facility's massive air conditioning unit was dripping onto the enclosure right above the SoC. We were, quite literally, debugging the effects of humidity. I should have included that story in the post itself.
I did not interpret the article as you did, and thought it was clear throughout that the author was talking about an individual read from memory, not reading all of a given amount of memory. "Memory access, both in theory and in practice, takes O(N^⅓) time: if your memory is 8x bigger, it will take 2x longer to do a read or write to it." Emphasis on "a read or write".
I read "in 2x time you can access 8x as much memory" as "in 2x time you can access any byte in 8x as much memory", not "in 2x time you can access the entirety of 8x as much memory". Though I agree that the wording of that line is bad.
In normal big-O notation, accessing N bytes of memory is already O(N), and I think it's clear from context that the author is not claiming that you can access N bytes of memory in less time than O(N).
Nobody has ever had this confusion about the access time of hash tables except maybe in the introductory class. What you’re describing is the same reasoning as any data structure. Which is correct. Physical memory hierarchies are a data structure. Literally.
This is completely false. All regularly cited algorithm complexity classes are based on estimating a memory access as an O(1) operation. For example, if you model memory access as O(N^1/3), linear search worse case is not O(N), it is O(N^4/3): in the worse case you have to make N memory accesses and N comparisons, and if each memory access in N^1/3 time, this requires N^4/3 + N time, which is O(N^4/3).
> linear search worse case is not O(N), it is O(N^4/3)
No, these are different 'N's. The N in the article is the size of the memory pool over which your data is (presumably randomly) distributed. Many factors can influence this. Let's call this size M. Linear search is O(N) where N is the number of elements. It is not O(N^4/3), it is O(N * M^1/3).
There's a good argument to be made that M^(1/3) should be considered a constant, so the algorithm is indeed simply O(N). If you include M^(1/3), why are you not also including your CPU speed? The speed of light? The number of times the OS switches threads during your algorithm? Everyone knows that an O(N) algorithm run on the same data will take different speeds on different hardware. The point of Big-O is to have some reasonable understanding of how much worse it will get if you need to run this algorithm on 10x or 100x as much data, compared to some baseline that you simply have to benchmark because it relies on too many external factors (memory size being one).
> All regularly cited algorithm complexity classes are based on estimating a memory access as an O(1) operation
That's not even true: there are plenty of "memory-aware" algorithms that are designed to maximize the usage of caching. There are abstract memory models that are explicitly considered in modern algorithm design.
You can model things as having M be a constant - and that's what people typically do. The point is that this is a bad model, that breaks down when your data becomes huge. If you're tying to see how an algorithm will scale from a thousand items to a billion items, then sure - you don't really need to model memory access speeds (though even this is very debatable, as it leads to very wrong conclusions, such as thinking that adding items to the middle of a linked list is faster than adding them to the middle of an array, for large enough arrays - which is simply wrong on modern hardware).
However, if you want to model how your algorithm scales to petabytes of data, then the model you were using breaks down, as the cost of memory access for an array that fits in RAM is much smaller than the cost of memory access for the kind of network storage that you'll need for this level of data. So, for this problem, modeling memory access as a function of N may give you a better fit for all three cases (1K items, 1G items, and 1P items).
> That's not even true: there are plenty of "memory-aware" algorithms that are designed to maximize the usage of caching.
I know they exist, but I have yet to see any kind of popular resource use them. What are the complexities of Quicksort and Mergesort in a memory aware model? How often are they mentioned compared to how often you see O(N log N) / O(N²)?
> It is not O(N^4/3), it is O(N * M^1/3). There's a good argument to be made that M^(1/3) should be considered a constant
Math isn't mathing here. If M^1/3 >> N, like in memory-bound algorithms, then why should we consider it a constant?
> The point of Big-O is to have some reasonable understanding of how much worse it will get if you need to run this algorithm on 10x or 100x as much data
And this also isn't true and can be easily proved by contradiction. O(N) linear search over array is sometimes faster than O(1) search in a hash-map.
This is untrue, algorithms measure time complexity classes based on specific operations, for example comparison algorithms are cited as typically O(n * log(n)) but this refers to the number of comparisons irrespective of what the complexity of memory accesses is. For example it's possible that comparing two values to each other has time complexity of O(2^N) in which case sorting such a data structure would be impractical, and yet it would still be the case that the sorting algorithm itself has a time complexity of O(N log(N)) because time complexity is with respect to some given set of operations.
Another common scenario where this comes up and actually results in a great deal of confusion and misconceptions are hash maps, which are said to have a time complexity of O(1), but that does not mean that if you actually benchmark the performance of a hash map with respect to its size, that the graph will be flat or asymptotically approaches a constant value. Larger hash maps are slower to access than smaller hash maps because the O(1) isn't intended to be a claim about the overall performance of the hash map as a whole, but rather a claim about the average number of probe operations needed to lookup a value.
In fact, in the absolute purest form of time complexity analysis, where the operations involved are literally the transitions of a Turing machine, memory access is not assumed to be O(1) but rather O(n).
Time complexity of an algorithm specifically refers to the time it takes an algorithm to finish. So if you're sorting values where a single comparison of two values takes O(2^n) time, the time complexity of the sort can't be O(n log n).
Now, you very well can measure the "operation complexity" of an algorithm, where you specify how many operations of a certain kind it will do. And you're right that typically comparison sorting algorithms complexities are often not time complexities, they are the number of comparisons you'll have to make.
> hash maps, which are said to have a time complexity of O(1), but that does not mean that if you actually benchmark the performance of a hash map with respect to its size, that the graph will be flat or asymptotically approaches a constant value.
This is confused. Hash maps have an idealized O(1) average case complexity, and O(n) worse case complexity. The difficulty with pinning down the actual average case complexity is that you need to trade off memory usage vs chance of collisions, and people are usually quite sensitive to memory usage, so that they will end up having more and more collisions as n gets larger, while the idealized average case complexity analysis assumes that the hash function has the same chance of collisions regardless of n. Basically, the claim "the average case time complexity of hashtables is O(1)" is only true if you maintain a very sparse hashtable, which means its memory usage will grow steeply with size. For example, if you want to store thousands of arbitrary strings with a low chance of collisions, you'll probably need a bucket array that's a size like 2^32. Still, if you benchmark the performance of hashtable lookup with respect to its size, while using a very good hash function, and maintaining a very low load ratio (so, using a large amount of memory), the graph will indeed be flat.
> if you model memory access as O(N^1/3), linear search worse case is not O(N), it is O(N^4/3)
This would be true if we modeled memory access as Theta(N^{1/3}) but that's not the claim. One can imagine the data organized/prefetched in such a way that a linear access scan is O(1) per element but a random access is expected Theta(N^{1/3}). You see this same sort of pattern with well-known data structures like a (balanced) binary tree; random access is O(log(n)), but a linear scan is O(n).
{kind=link}
reply