It's pretty funny to see this blog post, when I have been running Ollama on my AMD RX 6650 for weeks :D
They have shipped ROCm containers since 0.1.27 (21 days ago). This blog post seems to be published along with the latest release, 0.1.29. I wonder what they actually changed in this release with regards to AMD support.
Also: see this issue[0] that I made where I worked through running Ollama on an AMD card that they don't "officially" support yet. It's just a matter of setting an environment variable.
I'm thrilled to see support for RX 6800/6800 XT / 6900 XT. I bought one of those for an outrageous amount during the post-covid shortage in hopes that I could use it for ML stuff, and thus far it hasn't been very successful, which is a shame because it's a beast of a card!
Sad to see that the cut off is just after 6700 XT which is what is in my desktop. They indicate more devices are coming, hopefully that includes some of the more modern all in one chips with RDNA 2/3 from AMD as well.
I've been using my 6750XT for more than a year now on all sorts of AI projects. Takes a little research and a few env vars but no need to wait for "official" support most of the time.
HSA_OVERRIDE_GFX_VERSION=10.3.0 seems to be the magic words.
You can invoke it directly via `HSA_OVERRIDE_GFX_VERSION=10.3.0 ollama serve`, but I added this line to the systemd unit at /etc/systemd/system/ollama.service:
I'm not sure why Ollama garners so much attention. It has limited value - used for only experimenting with models + cannot support more than 1 model at a time. It's not meant for production deployments. Granted that it makes the experimentation process super easy but for something that relies on llama.cpp completely and whose main value proposition is easy model management I'm not sure it deserves the brouhaha people are giving it.
Edit: what do you do after the initial experimentation? you need to deploy these models eventually to production. I'm not even talking about giving credit to llama.cpp, just mentioning that this product is gaining disproportionate attention and kudos compared to the value it delivers. Not denying that it's a great product.
I am probably not the demographics you expect. I don’t do “production” in that sense, but I have ollama running quite often when I am working, as I use it for RAG and as a fancy knowledge extraction engine. It is incredibly useful:
- I can test a lot of models by just pulling them (very useful as progress is very fast),
- using their command line is trivial,
- the fact that it keeps running in the background means that it starts once every few days and stays out of the way,
- it integrates nicely with langchain (and a host of other libraries), which means that it is easy to set up some sophisticated process and abstract away the LLM itself.
> what do you do after the initial experimentation?
I just keep using it. And for now, I keep tweaking my scripts but I expect them to stabilise at some point, because I use these models to do some real work, and this work is not monkeying about with LLMs.
> I'm not even talking about giving credit to llama.cpp, just mentioning that this product is gaining disproportionate attention and kudos compared to the value it delivers.
For me, there is nothing that comes close in terms of integration and convenience. The value it delivers is great, because it enables me to do some useful work without wasting time worrying about lower-level architecture details. Again, I am probably not in the demographics you have in mind (I am not a CS person and my programming is usually limited to HPC), but ollama is very useful to me. Its reputation is completely deserved, as far as I am concerned.
The use case is exploratory literature review in a specific scientific field.
I have a setup that takes pdfs and does some OCR and layout detection with Amazon, and then bunch them with some internal reports. Then, I have a pipeline to write summaries of each document and another one to slice them into chunks, get embeddings and set up a vector store for a RAG chat bot. At the moment it’s using Mixtral and the command line. But I like being able to swap LLMs to experiments with different models and quantisation without hassle, and I more or less plan to set this up on a remote server to free some resources on my workstation so the web UI could come in handy. Running this locally is a must for confidentiality reasons. I’d like to get rid of Textract as well, but unfortunately I haven’t found a solution that’s even close. Tesseract in particular was very disappointing.
In my opinion, pre-built binaries and an easy-to-use front-end are things that should exist and are valid as a separate project unto themselves (see, e.g., HandBrake vs ffmpeg).
Using the name of the authors or the project you're building on can also read like an endorsement, which is not _necessarily_ desirable for the original authors (it can lead to ollama bugs being reported against llama.cpp instead of to the ollama devs and other forms of support request toil). Consider the third clause of BSD 3-Clause for an example used in other projects (although llama.cpp is licensed under MIT).
> Granted that it makes the experimentation process super easy
That's the answer to your question. It may have less space than a Zune, but the average person doesn't care about technically superior alternatives that are much harder to use.
The first 3 steps GP provided are literally just the steps for installation. The "value" you mentioned is just a packaged installer (or, in the case of Linux, apparently a `curl | sh` -- and I'd much prefer the git clone version).
On multiple occasions I've been modifying llama.cpp code directly and recompiling for my own purposes. If you're using ollama on the command line, I'd say having the option to easily do that is much more useful than saving a couple commands upon installation.
It should be fairly obvious that one can find alternative models and use them in the above command too.
Look, I’m not arguing that a prebuilt binary that handles model downloading has no value over a source build and manually pulling down gguf files. I just want to dispel some of the mystery.
Local LLM execution doesn’t require some mysterious voodoo that can only be done by installing and running a server runtime. It’s just something you can do by running code that loads a model file into memory and feeds tokens to it.
More programmers should be looking at llama.cpp language bindings than at Ollama’s implementation of the openAI api.
There are 5 commands in that README two comments up, 4 can reasonably fail (I'll give cd high marks for reliability). `make` especially is a minefield and usually involves a half-hour of searching the internet and figuring out which dependencies are a problem today. And that is all assuming someone is comfortable with compiled languages. I'd hazard most devs these days are from JS land and don't know how to debug make.
Finding the correct model weights is also a challenge in my experience, there are a lot of alternatives and it is often difficult to figure out what the differences are and whether they matter.
The README is clear that I'm probably about to lose an hour debugging if I follow it. It might be one of those rare cases where it works first time but that is the exception not the rule.
Just be aware that there’s a lot of expressive difference between building on top of an HTTP API vs on top of a direct interface to the token sampler and model state.
Python’s as good a choice as any for the application layer. You’re either going to be using PyTorch or llama-cpp-python to get the CUDA stuff working - both rely on native compiled C/C++ code to access GPUs and manage memory at the scale needed for LLMs. I’m not actually up to speed on the current state of the game there but my understanding is that llama.cpp’s less generic approach has allowed it to focus on specifically optimizing performance of llama-style LLMs.
I've seen more of the model fiddling, like logits restrictions and layer dropping, implemented in python, which is why I ask
Most of AI has centralized around Python, I see more of my code moving that way, like how I'm using LlamaIndex as my primary interface now, which supports ollama and many more model loaders / APIs
There is no "next", there is a whole world of people running LLMs locally on their computer and they are far more likely to switch between models on a whim every few days.
The average user isn't going to compile llama.cpp. They will either download a fully integrated application that contains llama.cpp and is able to read gguf files directly, like kobold.cpp or they are going to use any arbitrary front end like Silly Tavern which needs to connect to an inference server via an API and ollama is one of the easier inference servers to install and use.
I was trying to get AMD GPU support going in llama.cpp a couple weeks ago and just gave up after a while. 'rocminfo' shows that I have a GPU and, presumably, rocm installed but there were build problems I didn't feel like sorting out just to play with a LLM for a bit.
Even for just running a model locally, Ollama provided a much simpler "one click install" earlier than most tools. That in itself is worth the support.
Koboldcpp is also very, very good, plug and play, very complet web UI, nice little api with sse text streaming, vulkan accelerated, have an AMD fork...
Interestingly, Ollama is not popular at all in the "localllama" community (which also extends to related discords and repos).
And I think thats because of capabilities... Ollama is somewhat restrictive compared to other frontends. I have a littany of reasons I personally wouldn't run it over exui or koboldcpp, both for performance and output quality.
This is a necessity of being stable and one-click though.
For me all the projects which enable running & fine-tuning LLMs locally like llama.cpp, ollama, open-webui, unsolth etc. play a very important part in democratizing AI.
> what do you do after the initial experimentation? you need to deploy these models eventually to production
I built GaitAnalyzer[1], to analyze my gait laptop; I had deployed it briefly in production when I had enough credits to foot the AWS GPU bills. Ollama made it very simple to deploy the application, Anyone who has used docker before can now run GaitAnalyzer in their computer.
I mean, it takes something difficult like an LLM and makes it easy to run. It's bound to get attention. If you've tried to get other models like BERT based models to run you'll realize just how big the usability gains are running ollama than anything else in the space.
If the question you're asking is why so many folks are focused on experimentation instead of productionizing these models, then I see where you're coming from. There's the question of how much LLMs are actually being used in prod scenarios right now as opposed to just excited people chucking things at them; that maybe LLMs are more just fun playthings than tools for production. But in my experience as HN has gotten bigger, the number of posters talking about productionizing anything has really gone down. I suspect the userbase has become more broadly "interested in software" rather than "ships production facing code" and the enthusiasm in these comments reflects those interests.
FWIW we use some LLMs in production and we do not use ollama at all. Our prod story is very different than what folks are talking about here and I'd love to have a thread that focuses more on language model prod deployments.
Well you would be one of the few hundred people on the planet doing that. With local LLMs we're just trying to create a way for everyone else to use AI that doesn't require sharing all their data with them. First thing everyone asks for of course is how to turn the open source local llms into their own online service.
Ollama's purpose and usefulness is clear. I don't think anyone is disputing that nor the large usability gains ollama has driven. At least I'm not.
As far as being one of the few hundred on the planet, well yeah that's why I'm on HN. There's tons of publications and subreddits and fora for generic tech conversation. I come here because I want to talk about the unknowns.
> I come here because I want to talk about the unknowns.
Your knowns an are unknowns to some people and vice versa. This is a great strength of HN; on a whole lot of subject you’ll find people ranging from enthusiastic to expert. There are probably subreddits or discord servers tailored to narrow niches and that’s cool, but HN is not that. They are complementary, if anything. In contrast, HN is much more interesting and with a much better S/N ratio than generic tech subreddits, it’s not even comparable.
I've been using this site since 2008. This is my second account from 2009. HN very much used to be a tech niche site. I realize that for newer users to HN, the appeal is like r/programming or r/technology but with a more text oriented interface or higher SNR or whatever but this is a shift in audience and there are folks like I on this site who still want to use it for niche content.
There are still threads where people do discuss gory details, even if the topics aren't technical. A lot of the mapping articles on the site bring out folks with deep knowledge about mapping stacks. Alternate energy threads do it too. It can be like that for LLMs also, but the user base has to want this site to be more than just Yet Another Tech News Aggregator thread.
For me as of late I've come to realize that the current audience wants YATNE more than they want deep discussion here and so I modulate my time here accordingly. The LLM threads bring me here because experts like jart chime in.
> I've been using this site since 2008. This is my second account from 2009.
I did not really like HN back in the day because it felt too startup-y, but maybe I got a wrong impression. I much preferred Ars Technica and their forum (now, Ars is much less compelling).
> For me as of late I've come to realize that the current audience wants YATNE more than they want deep discussion here and so I modulate my time here accordingly.
I think it depends on the stories. Different subjects have different demographics, and I have almost completely stopped reading physics stuff because it is way too Reddit-like (and full of confident people asserting embarrassingly wrong facts). I can see how you could feel about fields closer to your interests being dumbed down by over-confident non-specialists.
There are still good, highly technical discussions, but it is true that the home page is a bit limited and inefficient to find them.
Few hundred on the planet? Are you kidding me? We're asking enterprises to run LLMs on-premise (I'm intentionally discounting the cloud scenario where the traffic rates are much higher). That's way more than a hundred and sorry to break it to you that Ollama is just not going to cut it.
No need to be angry about this. Tech folks should be discussing this collectively and collaboratively. There's space for everything from local models running on smartphones all the way up to OpenAI style industrialized models. Back when social networks were first coming out, I used to read lots of comments about deploying and running distributed systems. I remember reading early incident reports about hotspotting and consistent hashing and TTL problems and such. We need to foster more of that kind of conversation for LMs. Sadly right now Xitter seems to be the best place for that.
Not angry. Having a discussion :-). It just amazes me how the HN crowd is more than happy with just trying out a model on their machine and calling it a day and not seeing the real picture ahead. Let ignore perf concerns for a moment. Let's say I want to run it on a shared server in the enterprise network so that any application can make use of it. Each application might want to use a model of their choosing. Ollama will unload/load/unload models as each new request arrives. Not sure if folks here are realizing this :-)
I am 100% uninterested in your production deployment of rent seeking behavior for tools and models I can run myself. Ollama empowers me to do more of that easier. That’s why it’s popular.
It's nice for personal use which is what I think it was built for, has some nice frontend options too. The tooling around it is nice, and there are projects building in rag etc. I don't think people are intending to deploy days services through these tools
FWIW Ollama has no concurrency support even though llama.cpp's server component (the thing that Ollama actually uses) supports it. Besides, you can't have more than 1 model running. Unloading and loading models is not free. Again, there's a lot more and really much of the real optimization work is not in Ollama; it's in llama.cpp which is completely ignored in this equation.
I'm pretty sure their primary focus right now is to gain as much mindshare as possible and they seem to be doing a great job of it. If you look at the following GitHub metrics:
The number of people engaging with ollama is twice that of llama.cpp. And there hasn't been a dip in people engaging with Ollama in the past 6 months. However, what I do find interesting with regards to these two projects is the number of merged pull requests. If you click on the "Groups" tab and look at "Hooray", you can see llama.cpp had 72 contributors with one or more merged pull requests vs 25 for Ollama.
For Ollama, people are certainly more interested in commenting and raising issues. Compare this to llama.cpp, where the number of people contributing code changes is double that of Ollama.
I know llama.cpp is VC funded and if they don't focus on make using llama.cpp as easy to use as Ollama, they may find themselves doing all the hard stuff with Ollama reaping all the benefits.
Of course, you can support concurrent requests. But Ollama doesn't support it and it's not meant for this purpose and that's perfectly ok. That's not the point though. For fast/perf scenarios, you're better off with vllm.
This is not CUDA's moat. That is on the R&D/training side.
Inference side is partly about performance, but mostly about cost per token.
And given that there has been a ton of standardization around LLaMA architectures, AMD/ROCm can target this much more easily, and still take a nice chunk of the inference market for non-SOTA models.
Hypotheticals don't matter. The average user won't have the most expensive GPU and when it comes to VRAM AMD is half as expensive so they lead in this area.
Not sure why you're downvoted, but as far as I've heard AMD cards can't beat 4090 - yet.
Still, I think AMD will catch or overtake NVidia in hardware soon, but software is a bigger problem. Hopefully the opensource strategy will pay off for them.
A RTX 4090 is about twice the price of and 50%-ish faster than AMD's most expensive consumer card so I'm not sure anyone really expects it to ever surpass a 4090.
A 7900 XTX beating a RTX 4080 at inference is probably a more realistic goal though I'm not sure how they compare right now.
The 4080 is $1k for 16gb of VRAM, and the 7900 is $1k for 24gb of VRAM. Unless you're constantly hammering it with requests, the extra speed you may get with CUDA on a 4080 is basically irrelevant when you can run much better models at a reasonable speed.
Please check out https://github.com/geniusrise - tool for running llms and other stuff, behaves like docker compose, works with whatever is supported by underlying engines:
Feels like all of this local LLM stuff is definitely pushing people in the direction of getting new hardware, since nothing like RX 570/580 or other older cards sees support.
On one hand, the hardware nowadays is better and more powerful, but on the other, the initial version of CUDA came out in 2007 and ROCm in 2016. You'd think that compute on GPUs wouldn't require the latest cards.
The Ollama backend llama.cpp definitely supports those older cards with the OpenCL and Vulkan backends, though performance is worse than ROCm or CUDA. In their Vulkan thread for instance I see people getting it working with Polaris and even Hawaii cards.
No new hardware needed. I was shocked that Mixtral runs well on my laptop, which has a so-so mobile GPU. Mixtral isn't hugely fast, but definitely good enough!
Thanks, wow, amazing that you can already run a small model with so little ram. I need to buy a new laptop, guess more than 16 gb on a macbook isn't really needed
I've run LLMs and some of the various image models on my M1 Studio 32GB without issue. Not as fast as my old 3080 card, but considering the Mac all in has about a 5th the power draw, it's a lot closer than I expected. I'm not sure of the exact details but there is clearly some secret sauce that allows it to leverage the onboard NN hardware.
Super easy. You can just head down to https://lmstudio.ai and pick up an app that lets you play around. It's not particularly advanced, but it works pretty well.
It's mostly optimized for M-series silicon, but it also technically works on Windows, and isn't too difficult to trick into working on Linux either.
Looks super cool, though it seems to be missing a good chunk of features, like the ability to change the prompt format. (Just installed it myself to check out all the options.) All the other missing stuff I can see though is stuff that LM Studio doesn't have either (such as a notebook mode). If it has a good chat mode then that's good enough for most!
llama.cpp added first class support for the RX 580 by implementing the vulkan backend. There are some issues on older kernel amdgpu code where a llm process VRAM is never reloaded if it gets kicked out to GTT (in 5.x kernels) but overall it's much faster than the clBLAST opencl implementation.
The compatibility matrix is quite complex for both AMD and NVIDIA graphics cards, and completely agree: there is a lot of work to do, but the hope is to gracefully fall back to older cards.. they still speed up inference quite a bit when they do work!
Just downloaded this and gave it a go. I have no experience with running any local models, but this just worked out of the box on my 7600 on Ubuntu 22. This is fantastic.
Yep, and it deserves the credit! He who writes the cuda kernel (or translates it) controls the spice.
I had wrapped this and had it working in Ollama months ago as well: https://github.com/ollama/ollama/pull/814. I don't use Ollama anymore, but I really like the way they handle device memory allocation dynamically, I think they were the first to do this well.
Ollama does a nice job of looking at how much VRAM the card has and tuning the number of gpu layers offloaded. Before that, I mainly just had to guess. It's still a heuristic, but I thought that was neat.
I'm mainly just using llama.cpp as a native library now, mainly for the direct access to more of llama's data structures, and because I have a sort of unique sampler setup.
I’m curious as to how they pulled this off. OpenCL isn’t that common in the wild relative to Cuda. Hopefully it can become robust and widespread soon enough. I personally succumbed to the pressure and spent a relative fortune on a 4090 but wish I had some choice in the matter.
Another giveaway that it's ROCm is that it doesn't support the 5700 series...
I'm really salty because I "upgraded" to a 5700XT from a Nvidia GTX 1070 and can't do AI on the GPU anymore, purely because the software is unsupported.
But, as a dev, I suppose I should feel some empathy that there's probably some really difficult problem causing 5700XT to be unsupported by ROCm.
I tried it recently and couldn't figure out why it existed. It's just a very feature limited app that doesn't require you to know anything or be able to read a model card to "do AI".
It's just because it's convenient. I wrote a rich text editor front end for llama.cpp and I originally wrote a quick go web server with streaming using the go bindings, but now I just use ollama because it's just simpler and the workflow for pulling down models with their registry and packaging new ones in containers is simpler. Also most people who want to play around with local models aren't developers at all.
I'm not sure why you are assuming that ollama users are developers when there are at least 30 different applications that have direct API integration with ollama.
Eh, I've been building native code for decades and hit quite a few roadblocks trying to get llama.cpp building with cuda support on my Ubuntu box. Library version issues and such. Ended up down a rabbit hole related to codenames for the various Nvidia architectures... It's a project on hold for now.
Weirdly, the Python bindings built without issue with pip.
Edited it out of my original comment because I didn't want to seem ranty/angry/like I have some personal vendatta, as opposed to just being extremely puzzled, but it legit took me months to realize it wasn't a GUI because of how it's discussed on HN, i.e. as key to democratizing, as a large, unique, entity, etc.
Hadn't thought about it recently. After seeing it again here, and being gobsmacked by the # of genuine, earnest, comments assuming there's extensive independent development of large pieces going on in it, I'm going with:
- "The puzzled feeling you have is simply because llama.cpp is a challenge on the best of days, you need to know a lot to get to fully accelerated on ye average MacBook. and technical users don't want a GUI for an LLM, they want a way to call an API, so that's why there isn't content extalling the virtues of GPT4All*. So TL;DR you're old and have been on computer too much :P"
but I legit don't know and still can't figure it out.
* picked them because they're the most recent example of a genuinely democratizing tool that goes far beyond llama.cpp and also makes large contributions back to llama.cpp, ex. GPT4All landed 1 of the 2 vulkan backends
OpenCL is as dead as OpenGL and the inference implementations that exist are very unperformant. The only real options are CUDA, ROCm, Vulkan and CPU. And Vulkan is a proper pain too, takes forver to build compute shaders and has to do so for each model. It only makes sense on Intel Arc since there's nothing else there.
You can use OpenCL just fine on Nvidia, but CUDA is just a superior compute programming model overall (both in features and design.) Pretty much every vendor offers something superior to OpenCL (HIP, OneAPI, etc), because it simply isn't very nice to use.
I suppose that's about right. The implementors are busy building on a path to profit and much less concerned about any sort-of lock-in or open standards--that comes much later in the cycle.
OpenCL is fine on Nvidia Hardware. Of course it's a second class citizen next to CUDA, but then again everything is a second class citizen on AMD hardware.
Apple killed off OpenCL for their platforms when they created Metal which was disappointing. Sounds like ROCm will keep it alive but the fragmentation sucks. Gotta support CUDA, OpenCL, and Metal now to be cross-platform.
OpenCL is a Khronos open spec for GPU compute, and what you’d use on Apple platforms before Metal compute shaders and CoreML were released. If you wanted to run early ML models on Apple hardware, it was an option. There was an OpenCL backend for torch, for example.
No idea. My best guess is their background is in graphics and games rather than machine learning. When CUDA is all you've ever known, you try just a little harder to find a way to keep using it elsewhere.
What's not reliable about it? On Linux hipcc is about as easy to use as gcc. On Windows it's a little janky because hipcc is a perl script and there's no perl interpreter I'll admit. I'm otherwise happy with it though. It'd be nice if they had a shell script installer like NVIDIA, so I could use an OS that isn't a 2 year old Ubuntu. I own 2 XTX cards but I'm actually switching back to NVIDIA on my main workstation for that reason alone. GPUs shouldn't be choosing winners in the OS world. The lack of a profiler is also a source of frustration. I think the smart thing to do is to develop on NVIDIA and then distribute to AMD. I hope things change though and I plan to continue doing everything I can do to support AMD since I badly want to see more balance in this space.
Last time I used AMD GPUs for GPGPU all it took was running hashcat to make the desktop rendering unstable. I'm sure leaving it run overnight would've gotten me a system crash.
That's always happened with NVIDIA on Linux too, because Linux is an operating system that actually gives you the resources you ask for. Consider using a separate video card that's dedicated to your video needs. Otherwise you should use MacOS or Windows. It's 10x slower at building code. But I can fork bomb it while training a model and Netflix won't skip a frame. Yes I've actually done this.
Given the price of top line NVidia cards, if they can be had at all, there's got to be a lot of effort going on behind the scenes to improve AMD support in various places.
Does anyone know how the AMD consumer GPU support on Linux has been implemented? Must use something else than ROCm I assume? Because ROCm only supports the 7900 XTX on Linux[1], while on Windows[2] support is from RX 6600 and upwards.
The newest release, 6.0.2, supports a number of other cards[1] and in general people are able to get a lot more cards to work than are officially supported. My 7900 XT worked on 6.0.0 for instance.
How hard would it be for AMD just to document the levels of support of different cards the way NVIDIA does with their "compute capability" numbers ?!
I'm not sure what is worse from AMD - the ML software support they provide for their cards, or the utterly crap documentation.
How about one page documenting AMD's software stack compared to NVIDIA, one page documenting what ML frameworks support AMD cards, and another documenting "compute capability" type numbers to define the capabilities of different cards.
Can anyone (maybe ollama contributors) explain to me the relationship between llama.cpp and ollama?
I always thought that ollama basically just was a wrapper (i.e. not much changes to inference code, and only built on top) around llama.cpp, but this makes it seem like it is more than that?
OS was possibly much more complicated to write at that time than CUDA is to write today. And competition is too strong. It might be more briefer than even Sun.
I wish AMD did well in the Stable Diffusion front because AMD is never greedy on VRAM. The 4060Ti 16GB(minimum required for Stable Diffusion in 2024) starts at $450.
AMD with ROCm is decent on Linux but pretty bad on Windows.
I run A1111, ComfyUI and kohya-ss on an AMD (6900XT which has 16GB, the minimum required for Stable Diffusion in 2024 ;)), though on Linux. Is it a Windows specific Issue for you?
Edit to add: Though apparently I still don't run ollama on AMD since it seems to disagree with my setup.
Or rather Nvidia is purposefully restricting VRAM to avoid gaming cards canibalizing their supremely profitable professional/server cards. AMD has no relevant server cards, so they have no reason to hold back on VRAM in consumer cards
Nvidia released consumer RTX 3090 with 24GB VRAM in Sep 2020, AMDs flagship release in that same month was 6900 XT with 16GB VRAM. Who is being restrictive here exactly?
Exactly. My friend was telling me that I was making a mistake for getting a 7900 XTX to run language models, when the fact of the matter is the cheapest NVIDIA card with 24 GB of VRAM is over 50% more expensive than the 7900 XTX. Running a high quality model at like 80 tps is way more important to me than running a way lower quality model at like 120 tps.
I cannot parse this. The Radeon RX 7900 XTX also has 24GB of vram, so how does it help you run higher quality models? I would understand if it had more ram.
Only the RX 7900 XTX has 24 GB of VRAM at its price point. If I went with an NVIDIA card, I would either have to spend over 50% more on the card, or use much worse models to fit on their 16 GB cards.
>time=2024-03-16T00:11:07.993+01:00 level=WARN source=amd_linux.go:50 msg="ollama >recommends running the https://www.amd.com/en/support/linux-drivers: amdgpu version file >missing: /sys/module/amdgpu/version stat /sys/module/amdgpu/version: no such file or >directory"
>time=2024-03-16T00:11:07.993+01:00 level=INFO source=amd_linux.go:85 msg="detected amdgpu >versions [gfx1031]"
>time=2024-03-16T00:11:07.996+01:00 level=WARN source=amd_linux.go:339 msg="amdgpu >detected, but no compatible rocm library found. Either install rocm v6, or follow manual >install instructions at https://github.com/ollama/ollama/blob/main/docs/linux.md#man..."
>time=2024-03-16T00:11:07.996+01:00 level=WARN source=amd_linux.go:96 msg="unable to verify >rocm library, will use cpu: no suitable rocm found, falling back to CPU"
>time=2024-03-16T00:11:07.996+01:00 level=INFO source=routes.go:1105 msg="no GPU detected"
Need to check how to install rocm on arch again... have done it once, a few moons back, but alas...
Ah, this is probably from missing ROCm libraries. The dynamic libraries are available as one of the release assets (warning: it's about 4GB expanded) https://github.com/ollama/ollama/releases/tag/v0.1.29 – dropping them in the same directory as the `ollama` binary should work.
Wow, that's a huge feature. Thank you, guys. By the way, does anyone have a preferred case where they can put 4 AMD 7900XTX? There's a lot of motherboards and CPUs that support 128 lanes. It's the physical arrangement that I have trouble with.
You don't need 128 lanes. 8x PCIe3 is more than enough, so for 4 cards that's 32. Most CPUs have about 40lanes. If you are not doing much that would be more than sufficient. Buy a PCIe riser. Go to amazon and search for it, a 16x to 16x PCIe riser. They go for about $25-$30 often about 20-30cm. If you want really long one, you can get one from China a 60cm for about the same price, you just have to wait for 3 weeks. That's what I did. Stuffing all those in a case is often difficult, so you have to go open rig. Either have the cables running out your computer and figuring out a way to support the cards while keeping them cool or just buy a small $20-$30 open rig frame.
Most CPUs have about 20 lanes (plus a link to the chipset).
On the one hand, they will be gen 4 or 5, so they're the equivalent of 40-80 gen 3 lanes.
On the other hand, you can only split them up if you have a motherboard that supports bifurcation. If you buy the wrong model, you're stuck dedicating the equivalent of 64 gen 3 lanes to a single card.
Edit: Actually, looking into it further, current Intel desktop processors will only run their lanes as 16(+4) or 8+8(+4). You can kind of make 4 cards work by using chipset-fed slots, but that sucks. You could also get a PCIe switch but those are very expensive. AMD will do 4+4+4+4(+4) on the right boards.
Ah ha, that's the part I was curious about. I was wondering if I could keep everything cool open rig. I'm waiting for the stuff to arrive: risers, board, CPU, GPUs. And I've been putting it off because I wasn't sure how about the case. All right then, open rig frame. Thank you!
Crypto mining didn't require significant bandwidth to the card. Mining-oriented motherboards typically only provisioned a single lane of PCIe to each card, and often used anemic host CPUs (like Celeron embedded parts).
Does LLM inference require significant bandwidth to the card? You have to get the model into VRAM, but that's a fixed startup cost, not a per-output-token cost.
Those are Navi 22/23/24 GPUs while the RX 6800+ GPUs are Navi 21. They have different ISAs... however, the ISAs are identical in all but name.
LLVM has recently introduced a unified ISA for all RDNA 2 GPUs (gfx10.3-generic), so the need for the environment variable workaround mentioned in the other comment should eventually disappear.
Ollama runs really, really slow on my MBP for Mistral - as in just a few tokens a second and it takes a long while before it starts giving a result. Anyone else run into this?
I've seen that it seems to be related to the amount of system memory available when ollama is started (??) however LM Studio does not have such issues.
There's a thing somewhat conspicuous in its absence - why isn't llama.cpp more directly credited and thanked for providing the base technology powering this tool?
All the other cool "run local" software seems to have the appropriate level of credit. You can find llama.cpp references in the code, being set up in a kind of "as is" fashion such that it might be OK as far as MIT licensing goes, but it seems kind of petty to have no shout out or thank you anywhere in the repository or blog or ollama website.
ollama has made a lot of nice contributions of their own. It's a good look to give a hat tip to the great work llama.cpp is also doing, but they're strictly speaking not required to do that in their advertising any more than llama.cpp is required to give credit to Google Brain, and I think that's because llama.cpp has pulled off tricks in the execution that Brain never could have accomplished, just as ollama has had great success focusing on things that wouldn't make sense for llama.cpp. Besides everyone who wants to know what's up can read the source code, research papers, etc. then make their own judgements about who's who. It's all in the open.
Newton only gave credits to "Gods". He said he stands on shoulders of Gods or something like that. But he never mentioned which Gods in particular, did he?
Fair. I didn't want to assume the worst, that it was just rhetorical slight of hand where "providing release packaging around an open source? you should credit it, at some point, somewhere." is implied as ridiculous, like asking llama.cpp to credit Google Brain. (Presumably, the implication is, for transformers / the Attention is All You Need paper)
If you're going to accuse me of rhetorical sleight of hand, you could start by at least spelling it correctly. This whole code stealing shtick is the kind of thing I'd expect from teenagers on 4chan not from someone who's been professionally trained like you. Many open source licenses like BSD-4 and X11 are actually written to prohibit people from "giving credit" in advertising in the manner you're expecting.
I'm 35, got my start in FOSS by working on Handbrake at 17 when ffmpeg was added.
There, I learned that you're supposed to credit projects you depend on, especially ones you depend on heavily.
I don't know why you keep finding ways to dismiss this simple fact. (really? spelling? on Saturday morning!?!? :D).
Especially with a strong record of open source contributions yourself.
Especially when your project is a classic example of A) building around llama.cpp and crediting it. I literally was thinking about llamafile when I wrote my original comment, before I realized who I was replying to.
I'm really trying to find a communication bridge here because I'm deeply curious, and I'd appreciate you doing the same if I'm lucky enough to get a reply from your august personage again. (seriously! no sarcasm!) My latest guesses:
- you saw this post far after the early tide of, ex., exaggerating for clarity, "anyone got the leak on the deets on how these wizards did this?!?!?! CUDA going down!"
- You're unaware Ollama _does not mention or credit llama.cpp at all_. Not once. Never. Google search query I used to verify my presumption is `site:ollama.com "llama.cpp"`. You will find that it is only mentioned in READMEs of repos of other peoples models, mentioning how they quantized.
- You're unaware this is an ongoing situation. Probably the 3rd thread I've seen in 3 months with decreasing #s of people treating it like a independent commercial startup making independent breakthroughs, and increasing #s of people being like "...why are you still doing this..."
For those unfamiliar, this is how jart's llamafile project credits llama.cpp, they certainly don't avoid it altogether, and they certainly don't seem to think its unnecessary. (source: https://github.com/Mozilla-Ocho/llamafile)
- 2nd sentence in README: "Our goal is to make open LLMs much more accessible to both developers and end users. We're doing that by combining ___llama.cpp___ with Cosmopolitan Libc into one framework"
- 21 mentions in README altogether.
- Under "How llamafile works", 3 mentions crediting llama.cpp in 5 steps.
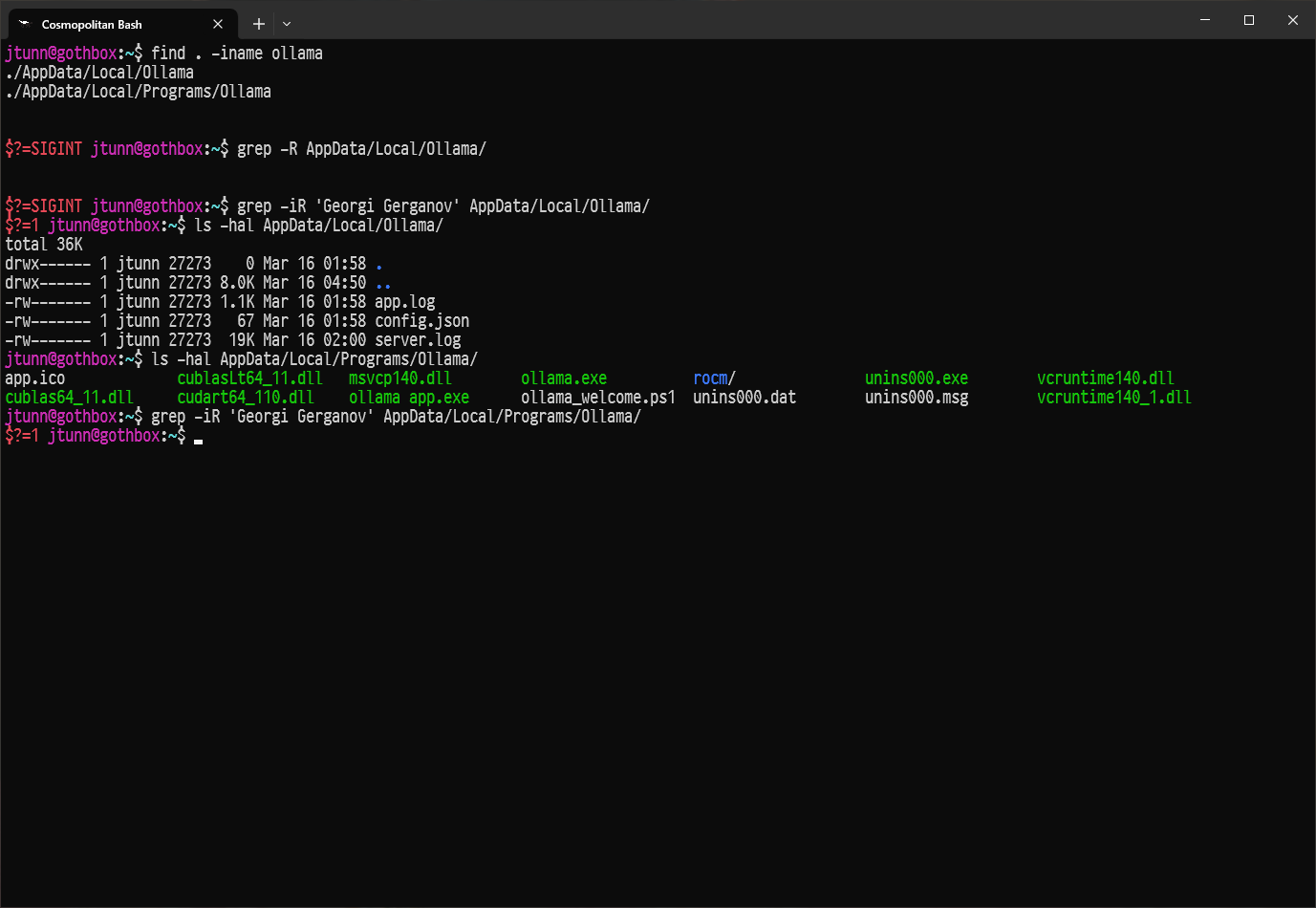
Look, there's a very simple way we can prove or disprove if ollama is doing something wrong. The MIT license (which llama.cpp uses) requires that their copyright notice accompany their source code. Here we can see that ollama is using llama.cpp (there's no secret about that) but they don't have any llama.cpp source code in their repo apparently https://github.com/search?q=repo%3Aollama%2Follama+Georgi+Ge... since they appear to be building it as a static library separately as some kind of workflow in their CI system.
But here's the twist: the MIT license requires that the copyright notice be distributed with the binary forms as well. That does not mean advertising. They're not required to mention it in their website or in their communiqués. The bare minimum requirement is that the copyright notice be present in their release artifacts.
llamafile solves this by embedding the copyright notice inside your llamafiles.
So let me install the latest Ollama on my Windows computer and see if they're doing this too. https://justine.lol/tmp/ollama-license-violation.png It would seem the answer is no. So yes, ollama appears to be violating the llama.cpp license, and probably the licenses of many other projects too. But not for the reasons we were discussing earlier.
Oops. They're violating the license on Linux too. It's also a little creepy that it used sudo on its own. So I've filed an issue here: https://github.com/ollama/ollama/issues/3185
lol, although you made me think--the history of computers has involved patching layer after layer of sediment on top of each other until the how things work 10 layers deep is forgotten. Imagine when local LLMs are five layers deep. It'll be like having machine spirits. You know how you have to yell to get the LLM to do what you want sometimes? That's what the future version of sudo will be like.
Who are these heathens who are going to ignore the basic language design work done by Kernighan & Ritchie? And whoever invented ++. Stroustrup didn't invent the C, the ++ or the notion of ++ing things in general. His contribution here is clearly quite small.
I thought the original argument for focusing on ollama alone was quite good. Once you get into dependencies it is turtles all the way down.
{kind=link}
They have shipped ROCm containers since 0.1.27 (21 days ago). This blog post seems to be published along with the latest release, 0.1.29. I wonder what they actually changed in this release with regards to AMD support.
Also: see this issue[0] that I made where I worked through running Ollama on an AMD card that they don't "officially" support yet. It's just a matter of setting an environment variable.
[0] https://github.com/ollama/ollama/issues/2870
Edit: I did notice one change, now the starcoder2[1] model works now. Before that would crash[2].
[1] https://ollama.com/library/starcoder2
[2] https://github.com/ollama/ollama/issues/2953